Exploration in Bandit Algorithms
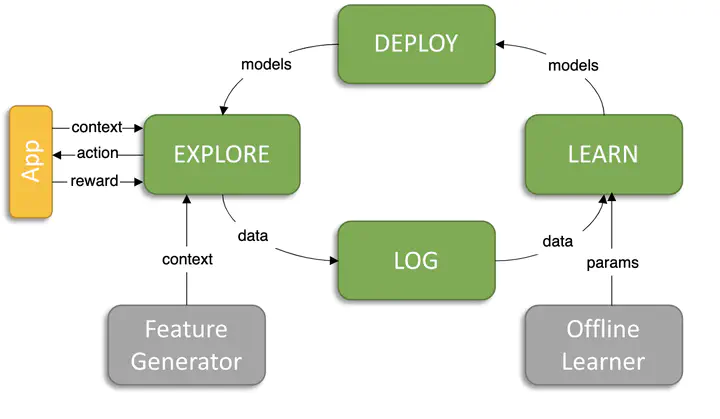
We propose a new bootstrap-based online algorithm for stochastic linear bandit problems. The key idea is to adopt residual bootstrap exploration, in which the agent estimates the next step reward by re-sampling the residuals of mean reward estimate. Our algorithm, residual bootstrap exploration for stochastic linear bandit (LinReBoot), estimates the linear reward from its re-sampling distribution and pulls the arm with the highest reward estimate. In particular, we contribute a theoretical framework to demystify residual bootstrap-based exploration mechanisms in stochastic linear bandit problems. The key insight is that the strength of bootstrap exploration is based on collaborated optimism between the online-learned model and the re-sampling distribution of residuals. Such observation enables us to show that the proposed LinReBoot secure a high-probability $\tilde{O}(d \sqrt{n})$ sub-linear regret under mild conditions. Our experiments support the easy generalizability of the LinReBoot principle in the various formulations of linear bandit problems and show the significant computational efficiency of LinReBoot.
More details will be updated by late September.